В Linux Kernel 5.7 будут ускорены сложные сопоставления по спискам в NetFilter
Разработчики подсистемы фильтрации и модификации сетевых пакетов Netfilter опубликовали набор патчей, значительно ускоряющих обработку больших списков сопоставления (nftables set), в которых требуется проверка сочетания подсетей, сетевых портов, протокола и MAC-адресов. Патчи уже приняты в ветку nf-next, которая будет предложена для включения в состав ядра Linux 5.7. Наиболее заметного ускорения удалось добиться благодаря задействованию инструкций AVX2 (в дальнейшем планируется опубликовать подобные оптимизации на базе инструкций NEON для ARM).
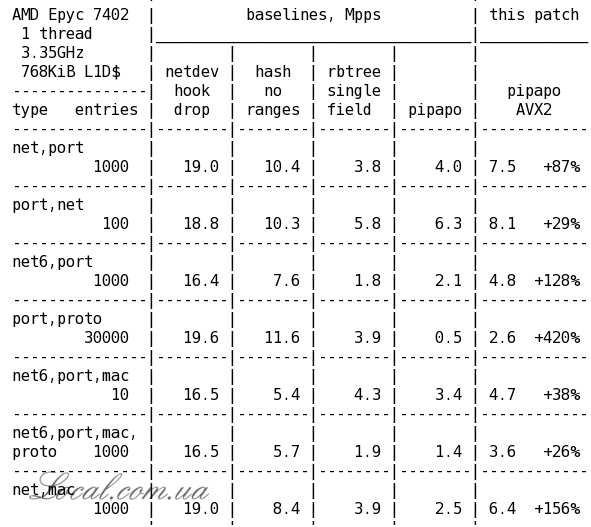
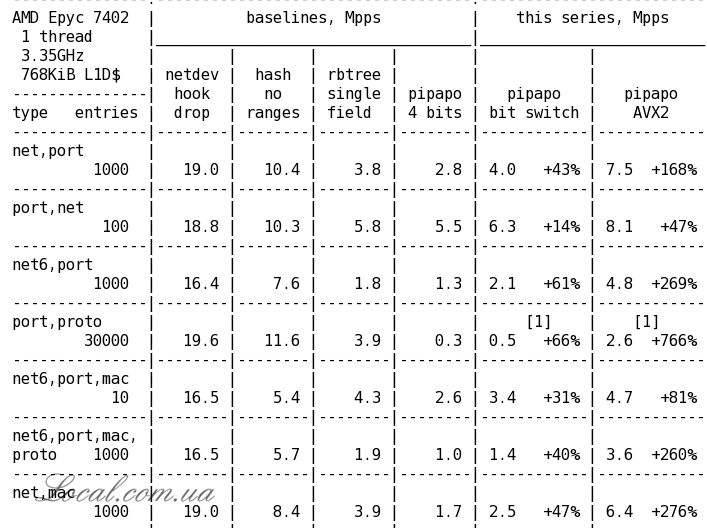
Оптимизации внесены в модуль nft_set_pipapo (PIle PAcket POlicies), решающий задачу сопоставления содержимого пакета с применяемыми в правилах фильтрации произвольными диапазонами состояния полей, такими как диапазоны IP и сетевых портов (nft_set_rbtree и nft_set_hash манипулируют сопоставлением интервалов и прямым отражением значений). Векторизированная при помощи 256-разрядных инструкций AVX2 верcия pipapo на системе с процессором AMD Epyc 7402 показала прирост производительности на 420% при разборе 30 тысяч записей, включающих связки порт-протокол. Прирост при сопоставлении связки из подсети и номера порта при разборе 1000 записей составил 87% для IPv4 и 128% для IPv6.
Другая оптимизация, позволяющая использовать 8-битовые группы сопоставления вместо 4-битовых, также показала ощутимый прирост производительности: 66% при разборе 30 тысяч записей порт-протокол, 43% - подсеть_IPv4-порт и 61% - подсеть_IPv6-порт. В сумме, с учётом оптимизаций AVX2, производительность pipapo увеличилась в указанных тестах на 766%, 168% и 269% соответственно. Полученные для сложных сопоставлений характеристики опережают проверки единичных полей в rbtree (за исключением теста связки порт+протокол), но пока отстают от прямых проверок при помощи хэшей и drop-обработчиков на базе netdev.

You should to log in